2025年7月2日,免费V2Ray节点大放送!10个订阅地址+20个高速免费节点,VPN、WinXray、2rayNG、BifrostV、ClashMellow、Qv2ray等工具随时可用,享受高质量代理带来的畅快感受!clash飞机场, 科学上网翻墙无费获取节点, 免费上网梯子, 无费梯子, 免费代理
 一、说明介绍与机场推荐
一、说明介绍与机场推荐
全球节点更新啦!涵盖美国、新加坡、加拿大、香港、欧洲、日本、韩国等地,提供10个全新订阅链接,轻松接入V2Ray/Clash/小火箭等科学上网工具,简单复制、粘贴即畅享全球网络自由!只需复制以下节点数据,导入或粘贴至v2ray/iso小火箭/winxray、2rayNG、BifrostV、Clash、Kitsunebi、V2rayN、V2rayW、Clash、V2rayS、Mellow、Qv2ray等科学上网工具,即可直接使用!
二,自用机场推荐
包月(不限时)最低5元起150GB流量:点我了解详情
同步电报群:https://t.me/xfxssr
永久发布页地址,防丢失https://sulinkcloud.github.io/
三,节点列表和测试速度
https://so.xfxssr.me/api/v1/client/subscribe?token=00bafcd9960ea59140048ed450ff8bf7
https://so.xfxssr.me/api/v1/client/subscribe?token=5cafe1382bbebe34b3b52848d32463e3
https://so.xfxssr.me/api/v1/client/subscribe?token=fe65f23aa380fc2fc61e8ad7510e4327
https://so.xfxssr.me/api/v1/client/subscribe?token=ea2854caeccc8446b4947cd39b8cc937
https://so.xfxssr.me/api/v1/client/subscribe?token=1156ec2723b6f1111ff4a5fca06112de
https://so.xfxssr.me/api/v1/client/subscribe?token=9474ff8aad9e59389c973db118bfa32d
https://so.xfxssr.me/api/v1/client/subscribe?token=8cb5f959345ff38101da26deb18dbbc5
https://so.xfxssr.me/api/v1/client/subscribe?token=05fdfda588eef57443afe45cfbd51b02
https://so.xfxssr.me/api/v1/client/subscribe?token=a057f9296c821e4751e834baf06032bc
https://so.xfxssr.me/api/v1/client/subscribe?token=d5e607d4cadd236e70c12fad7b3573e9
测试速度超快,看油管4k无压力
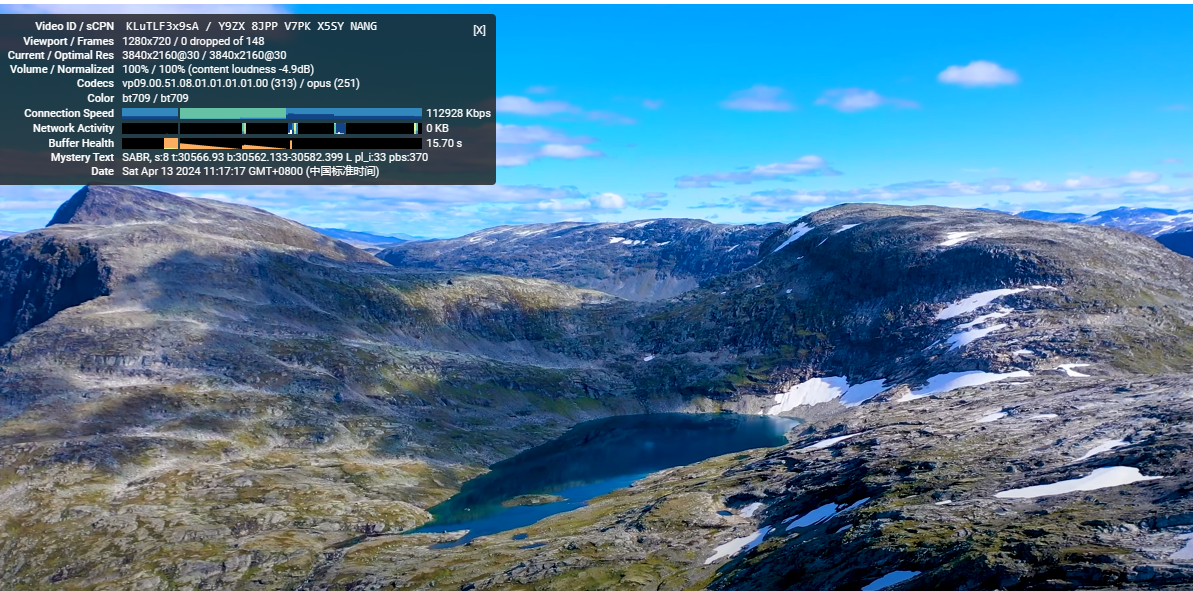
200个免费节点分享
https://cloud.xfxdesk.com/s/b9xT6
分割线
如何用 TensorFlow 训练一个手写数字识别模型?
解答步骤:
安装环境:
bash
pip install tensorflow numpy matplotlib pandas
加载数据集:使用 MNIST 手写数字数据集(TensorFlow 内置):
python
import tensorflow as tf
from tensorflow.keras import layers, models
# 加载数据
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 数据预处理
train_images = train_images.reshape(-1, 28, 28, 1).astype(“float32”) / 255
test_images = test_images.reshape(-1, 28, 28, 1).astype(“float32”) / 255
构建模型:
python
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation=’relu’),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation=’relu’),
layers.Flatten(),
layers.Dense(64, activation=’relu’),
layers.Dense(10, activation=’softmax’) # 10个数字类别
])
编译与训练:
python
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
评估模型:
python
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f”测试准确率:{test_acc}”)
保存模型:
python
model.save(‘handwriting_model.h5’)